The best Claude model for coding is Opus 4.5 for complex architecture, security, and code review, Sonnet 4 for everyday feature work, and Haiku 3.5 for high-volume mechanical tasks. Opus 4.5 now costs just 1.7x Sonnet - down from 5x - which makes a three-tier strategy that optimizes both quality and cost the practical default for most developers.
This guide covers when to use each model based on real-world coding scenarios. Our analysis draws on current Anthropic model documentation and independent research rather than sponsored placement. AI Productivity may earn a commission from links on this page; our model rankings remain editorially independent.
Methodology
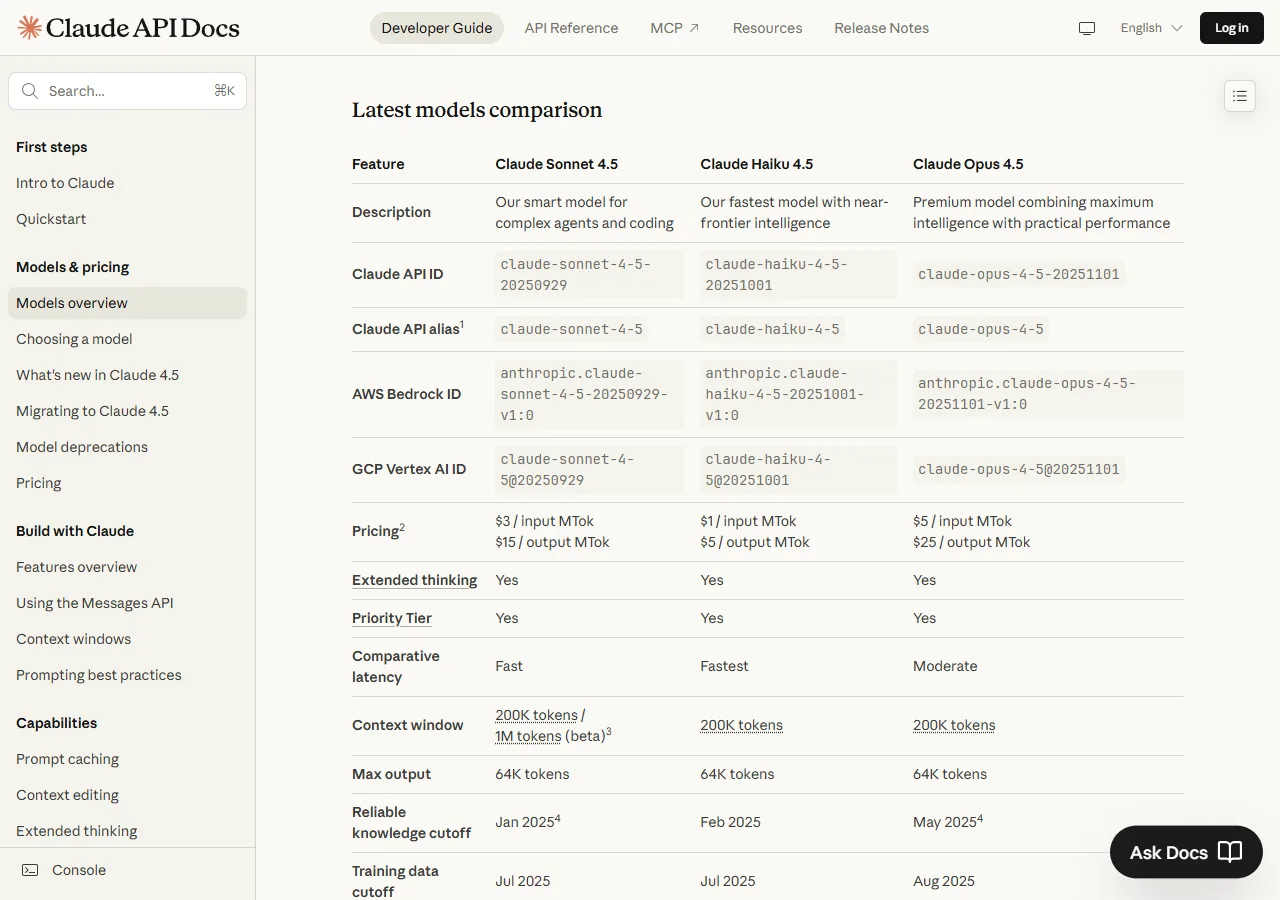
This comparison is based on each model’s current published API pricing and capability documentation, mapped against common coding task types. Anthropic’s February 2025 pricing update fundamentally changed the economics of model selection, as the official Claude models overview documents:
| Model | Input (1M tokens) | Output (1M tokens) | Relative Cost |
|---|---|---|---|
| Opus 4.5 | $5 | $25 | 1.7x Sonnet |
| Sonnet 4 | $3 | $15 | Baseline |
| Haiku 3.5 | $1 | $5 | 0.3x Sonnet |
The old calculus is obsolete. Opus at the former $15/$75 rate meant using it sparingly. At $5/$25, Opus becomes viable for any quality-sensitive task - code reviews, architecture, debugging, and security analysis.
Haiku, often overlooked, fills the gap for high-volume, routine tasks where speed and cost efficiency beat raw capability. Anthropic frames its lineup around exactly this task-to-model matching:
“We recommend starting with Claude Sonnet, our balance of intelligence and speed, and upgrading to Opus for the most complex tasks or Haiku for the highest throughput,” according to Anthropic’s official model-selection documentation.
The Models at a Glance: Which Claude Model for Coding Tasks
The Claude lineup splits coding work across three tiers: Opus 4.5 for maximum capability, Sonnet 4 for balanced everyday performance, and Haiku 3.5 for speed and cost efficiency.
Claude Opus 4.5
Claude Opus 4.5 is Anthropic’s flagship model, built for the hardest coding work. Opus excels at:
- Complex architectural reasoning
- Multi-file refactoring with consistency
- Security vulnerability detection
- Nuanced code review feedback
- Debugging subtle race conditions and edge cases
Best for: Tasks where getting it right the first time saves iteration cycles.
Claude Sonnet 4
The balanced workhorse. Sonnet handles:
- Most day-to-day coding tasks
- Feature implementation with clear requirements
- Test generation
- Documentation
- Straightforward debugging
Best for: 80% of development work where speed and quality both matter.
Claude Haiku 3.5
The efficiency specialist. Haiku excels at:
- Boilerplate generation
- Syntax transformations
- Code formatting and linting suggestions
- High-volume batch operations
- Quick lookups and explanations
Best for: Simple, well-defined tasks where speed and cost dominate.
Limitations: Skip Opus for mechanical syntax work, skip Sonnet for bulk batch jobs Haiku handles cheaper, and skip Haiku for multi-file refactors or security review. All three share knowledge cutoffs that lag current frameworks and cannot test their own output without an external runner.
How Do Claude Models Perform by Coding Task Type?
Claude model performance scales with task complexity: all three handle simple functions well, but only Opus reliably manages multi-file features, security review, and architecture design.
Code Generation
| Task Type | Haiku | Sonnet | Opus |
|---|---|---|---|
| Simple functions | Good | Excellent | Excellent |
| CRUD endpoints | Good | Excellent | Excellent |
| Complex algorithms | Adequate | Good | Excellent |
| Multi-file features | Poor | Good | Excellent |
| Architecture design | Poor | Adequate | Excellent |
Simple functions: All three models handle well-defined utility functions. Haiku is fastest, Sonnet adds better edge-case handling, and Opus rarely improves on Sonnet here - so Haiku or Sonnet wins on the cost/speed tradeoff.
Complex algorithms: Opus demonstrates clear advantages, producing more elegant solutions and considering edge cases unprompted. For a task like an O(1) LRU cache, Opus delivers a cleaner design and better memory efficiency.
Multi-file features: For features spanning multiple interdependent files, Opus maintains consistency and makes smarter architectural decisions, while Haiku struggles with cross-file context - so Opus wins on coherence.
Code Review and Debugging
| Task Type | Haiku | Sonnet | Opus |
|---|---|---|---|
| Syntax errors | Good | Good | Good |
| Logic bugs | Adequate | Good | Excellent |
| Security vulnerabilities | Poor | Good | Excellent |
| Performance issues | Poor | Adequate | Excellent |
| Architecture review | Poor | Adequate | Excellent |
Finding bugs: Sonnet identifies obvious bugs effectively, while Opus excels at subtle issues - race conditions, security vulnerabilities, and deep logic errors.
Security analysis: Opus’s reasoning depth catches vulnerabilities other models miss, and for security-sensitive code that quality difference justifies the cost.
Refactoring
Simple refactors: Renaming, extracting functions, and mechanical transformations work well across all models - use Haiku for efficiency.
Complex refactors: When refactoring changes fundamental approaches or depends on business logic, Opus produces cleaner results with fewer broken dependencies.
Limitations: These ratings are not absolute - on niche languages (Elixir, Zig, Roc) all three models trail their Python and TypeScript performance, Haiku can produce uncreative solutions, and Opus sometimes over-engineers simple problems.
Speed and Latency
Haiku is the fastest Claude model, completing a simple function in 1-2 seconds versus 2-4 seconds for Sonnet and 5-10 seconds for Opus. Real-world timing comparison:
| Task Type | Haiku | Sonnet | Opus |
|---|---|---|---|
| Simple function | 1-2s | 2-4s | 5-10s |
| Complex function | 2-4s | 5-10s | 15-30s |
| Multi-file changes | 5-10s | 15-30s | 45-90s |
| Code review | 2-5s | 5-15s | 20-45s |
For interactive development, Haiku and Sonnet’s speed compounds across iteration cycles and protects flow state; for background tasks, Opus’s thoroughness matters more once latency stops affecting your workflow.
Limitations: These latency numbers are best-case. Skip Opus for keystroke-driven flows like tab completion, where 15-90 second waits break concentration, and skip Sonnet for high-throughput batch pipelines where Haiku is far faster.
How Do Opus, Sonnet, and Haiku Compare on Pricing?
Opus 4.5 costs $5 input and $25 output per million tokens, Sonnet 4 costs $3 and $15, and Haiku 3.5 costs $1 and $5 - so Opus is 1.7x Sonnet and Haiku is roughly a third of Sonnet. Under the old $15/$75 Opus rate, one budget bought 100 Sonnet or only 20 Opus requests. At $5/$25 that same budget now buys about 60 Opus requests, while Haiku stretches to roughly 300 - large savings on high-volume, simple tasks.
Cost-per-task comparison
For a typical coding session (10,000 input tokens, 2,000 output tokens per task):
| Model | Cost per Task | Tasks per $10 |
|---|---|---|
| Opus 4.5 | $0.10 | 100 |
| Sonnet 4 | $0.06 | 167 |
| Haiku 3.5 | $0.02 | 500 |
Choose Haiku if
Choose Haiku 3.5 when the task is mechanical and high-volume - boilerplate, syntax transformations, linting, and batch jobs where speed and cost outweigh deep reasoning.
Optimal scenarios for Haiku:
- Boilerplate generation - Repetitive scaffolding, templates
- Syntax transformations - Format conversions, type annotations
- Linting and formatting - Style suggestions, code cleanup
- High-volume batch jobs - Processing many files identically
- Quick explanations - “What does this regex do?”
- Simple completions - Finishing obvious patterns
Example workflow: Adding TypeScript types to 50 utility functions, Haiku processes all 50 for roughly $0.50 versus $3 with Sonnet, at quality sufficient for mechanical transformations.
When NOT to use Haiku:
- Tasks requiring cross-file consistency
- Security-sensitive code
- Complex business logic
- Anything where “good enough” isn’t good enough
Choose Sonnet if
Choose Sonnet 4 for the bulk of day-to-day development - feature implementation, test generation, documentation, and interactive iteration where speed and quality both matter.
Optimal scenarios for Sonnet:
- Feature implementation - New functionality with clear requirements
- Test generation - Unit tests, integration tests
- Interactive development - Rapid iteration cycles
- Documentation - Comments, README updates, API docs
- Debugging standard issues - Obvious bugs, error traces
- Learning and exploration - Quick experiments, trying approaches
Example workflow: Creating a React component for user profile editing, Sonnet generates the component in about 3 seconds and applies review tweaks in another 2 - roughly 5 seconds total for an excellent result.
Choose Opus if
Choose Opus 4.5 for complex architecture, security-sensitive code, hard debugging, and code review - any task where getting it right the first time saves costly iteration cycles.
Optimal scenarios for Opus:
- Complex architecture - System design, major refactors
- Security-sensitive code - Authentication, encryption, data handling
- Debugging difficult issues - Subtle bugs, race conditions
- Code review - Thorough analysis of important changes
- Ambiguous requirements - Tasks needing interpretation
- Novel problems - Unusual challenges without established patterns
- Multi-file consistency - Features touching many interconnected files
Example workflow: Reviewing an authentication system, Opus analyzes it in about 30 seconds, identifies subtle vulnerabilities Sonnet missed, and provides remediation with security rationale.
How Should You Apply a Three-Tier Claude Model Strategy?
A three-tier Claude strategy routes each task by complexity: Haiku for mechanical work, Sonnet as the default, and Opus for reasoning-heavy or security-sensitive tasks. Deciding which Claude model for coding to use comes down to matching task complexity to model capability, and the flowchart below makes that routing explicit.
Decision Flowchart
The routing logic is a two-question filter. First, is the task mechanical or repetitive? If yes, route to Haiku. If no, ask the second question: does it require deep reasoning or security judgment? If yes, route to Opus; if no, route to Sonnet as the default.
Quick Reference
| Indicator | Model |
|---|---|
| ”Just format this” | Haiku |
| ”Add types to these files” | Haiku |
| ”Generate CRUD endpoints” | Haiku or Sonnet |
| ”Implement this feature” | Sonnet |
| ”Write tests for this” | Sonnet |
| ”Review this PR” | Opus |
| ”Debug this race condition” | Opus |
| ”Design the auth system” | Opus |
| ”Check for security issues” | Opus |
Escalation Pattern
Start simple and escalate when needed: categorize task complexity, start at the appropriate tier, review the output critically, move up a tier for complex cases, and track which tasks need which tier over time.
Limitations: A three-tier strategy is not for everyone - skip routing if a single default model keeps overhead below the savings, since a tier classifier carries real engineering cost.
Tool-Specific Implementation
Each coding tool exposes its own way to pick a Claude model: Claude Code uses a --model flag, Cursor sets a model per context, and the API selects it in code.
Claude Code (CLI)
In Claude Code, the --model flag overrides the default Sonnet model per command:
claude "create user validation function" # default: Sonnet
claude --model opus "review this auth system" # complex work
claude --model haiku "add JSDoc to utils/" # batch operationsConfigure defaults in settings for automatic tier selection.
Cursor IDE
Configure model selection per-context:
- Tab completion: Haiku (speed critical)
- Quick edits: Sonnet
- Composer (multi-file): Opus
- Chat/review: Opus
API Integration
For direct API use, a small helper routes by task type and complexity:
def get_model_for_task(task_type: str, complexity: str) -> str:
if task_type in ["format", "lint", "annotate", "boilerplate"]:
return "claude-3-5-haiku-20241022" # mechanical
if complexity == "high" or task_type in ["review", "security"]:
return "claude-opus-4-5-20250120" # complex
return "claude-sonnet-4-20250514" # defaultLimitations: Per-tool routing requires an enterprise tier in GitHub Copilot on plans that enforce one model, and Cursor’s composer loses context fidelity on monolithic files with weak boundaries.
Best Picks by Use Case
The best Claude model for a real project is rarely a single model - it is a mix, with Opus planning and reviewing, Haiku scaffolding, and Sonnet implementing.
Scenario 1: Building a New Feature
Task: Add shopping cart functionality to an e-commerce site. Use Opus to plan the cart data model and API structure, Haiku to generate boilerplate component files and types, Sonnet to implement the cart service and routes plus tests, then Opus for a final security and architecture review.
Scenario 2: Debugging a Production Issue
Task: Users intermittently cannot complete checkout. Use Opus for the initial log analysis and the deep root-cause dive into the race condition, Haiku to add quick logging instrumentation, Sonnet to implement and test fixes, then Opus to verify the fix is complete.
Scenario 3: Large-Scale Refactoring
Task: Migrate a codebase from JavaScript to TypeScript. Use Opus to plan the migration and design the type system for complex domains, Haiku to add basic types across files, and Sonnet to handle generic types then test and fix type errors.
What Are the Most Common Claude Model Selection Mistakes?
The most common Claude model selection mistakes are defaulting to one model for everything, using Haiku for complex work, over-using Opus, and ignoring the new Opus pricing. Each is fixable by matching the model to the task.
Mistake 1: Always using one model. This misses optimal cost/quality tradeoffs - match the model to task characteristics, since a three-tier approach saves money and improves quality.
Mistake 2: Using Haiku for complex tasks. This causes poor output, more iterations, and technical debt - reserve Haiku for truly mechanical work and use Sonnet as a minimum when judgment is required.
Mistake 3: Using Opus for everything. This slows development and adds unnecessary cost - most tasks do not need Opus’s depth, so save it for architecture, security, and debugging.
Mistake 4: Ignoring the new pricing. Treating Opus as “special occasions only” is outdated - at 1.7x Sonnet cost, Opus is viable for any quality-sensitive work, so recalibrate your defaults.
Mistake 5: Switching models mid-task. This causes context loss and inconsistent output - assess complexity upfront and commit to one model.
Selection Criteria
The most reliable selection criteria are your own measured outcomes: track task types, A/B test models on similar tasks, and measure time, quality, and cost. Build decision rules from what works for your codebase, recording each run in a simple table:
| Date | Task | Model | Time | Quality | Cost |
|---|---|---|---|---|---|
| 2/1 | API endpoint | Sonnet | 5s | Good | $0.06 |
| 2/1 | Auth review | Opus | 45s | Excellent | $0.10 |
| 2/1 | Add types | Haiku | 2s | Good | $0.02 |
Conclusion
The right Claude model for coding depends on the task: use Haiku for mechanical work, Sonnet for daily development, and Opus for architecture, security, and complex debugging. The three-tier Claude strategy maximizes value across the capability-cost spectrum - roughly 30% of tasks suit Haiku, 50% suit Sonnet, and 20% justify Opus.
At 1.7x Sonnet instead of 5x, quality-sensitive work should now default to Opus. Categorize tasks by complexity, match each to the right tier, and track outcomes to refine your rules - whether you access these models through Claude Code, GitHub Copilot, or Cursor.
FAQ
Common questions about choosing a Claude model for coding are answered below.
Q: Is Claude 4 or 3.5 better for coding?
Claude 4-generation models are better for coding than 3.5-generation ones. Opus 4.5 and Sonnet 4 outperform Haiku 3.5 on reasoning, multi-file consistency, and security analysis, while Haiku 3.5 remains the right pick only for mechanical, high-volume tasks where speed and cost matter most.
Q: Is Claude 3.7 or 4 better for coding?
Claude 4 is better for coding than Claude 3.7. The Claude 4 generation - Opus 4.5 and Sonnet 4 - delivers stronger architectural reasoning, cleaner multi-file refactors, and deeper debugging than the earlier 3.7 release, so the current Claude 4 lineup should be the default for serious coding work.
Q: Is Claude 4.5 the best for coding?
Claude Opus 4.5 is the best Claude model for the most demanding coding tasks - architecture, security review, and subtle debugging. For everyday feature work, Sonnet 4 is the better value, so “best” depends on the task rather than always pointing to a single model.
Q: How to choose which model to use in a Claude code?
To choose a model in Claude Code, pass the --model flag - for example claude --model opus for complex work or claude --model haiku for batch operations - or set a default in your settings. Match the model to task complexity: Haiku for mechanical tasks, Sonnet as the default, and Opus for reasoning-heavy or security-sensitive work.
Related Reads
These guides go deeper on Claude coding tools and rival AI assistants:
- Claude Review - Full review of Anthropic’s AI assistant
- Claude Code Review - CLI-based AI coding assistant
- Cursor Review - AI-first code editor
- GitHub Copilot Review - AI pair programmer
- Claude Code Prompt Engineering - Master prompting techniques for better code generation
- Claude Code Hooks Deep Dive - Automate workflows with custom hooks
- Best AI Coding Assistants 2026 - Compare Claude with GitHub Copilot, Cursor, and more
- GitHub Copilot vs Cursor vs Gemini - Head-to-head IDE comparison
- 5 Best AI Tools for Coding in 2026
- Future of AI Coding Assistants: 4 Tools Shaping Development in 2026
- JetBrains AI Assistant: Complete Guide to AI Pro & Ultimate
External Resources
The official Anthropic sources below carry the current pricing and model specifications cited here:
- Claude API Pricing - Current model pricing
- Claude Documentation - Official API docs and guides
- Claude Model Overview - Model capabilities and specifications